Update: Micron released B218 in July 2015 to resolve a critical issue with command time outs. Micron highly recommends upgrading to this firmware release.
A common PCIe flash card for PernixData customers to use is the Micron P420m in their environment. It’s a very high performing and cost effective PCIe card and has a variety of applications.
Like all hardware devices, the p420m has firmware that occasionally needs to be updated. To perform the firmware update, we’re going to download the Micron rssdm utility (packaged with the ESXi drivers) on Micron’s site in the Support Pack for Linux and VMware package. As of January 2015, the support pack B145.03 from September 2014 is still current.
The first step to determining which firmware version the card is running is to install rssdm. Put the host into maintenance mode, copy the vib for your version of ESXi to the host, and run the esxcli software vib install -v command and reboot the host.
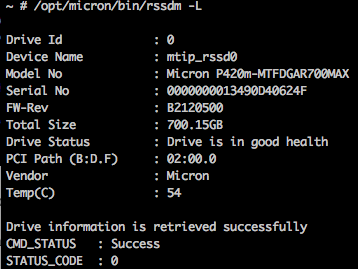
Once the host is back up, log in and execute the /opt/micron/bin/rssdm -L command to see the firmware version of the card.

As you can see, my card is running firmware version B2100600 and needs to be updated. At the time this article is posted, current firmware version is B2120500. We’re going to copy the new firmware to the host or shared datastore and perform the upgrade.
With the host in maintenance mode and the device removed from the FVP Cluster, copy the B145.03.00.ubi firmware image downloaded from the Micron Support Pack above to a location accessible by the host. The B145.03.00.ubi file will be in the Unified Image folder.
Then execute /opt/micron/bin/rssdm -T /path/to/file/B145.03.00.ubi -n 0

Once it’s complete, reboot the host.
When the host is back up, verify the new firmware is active.
Secure erase the drive by executing: /opt/micron/bin/rssdm -X -n 0 -p ffff
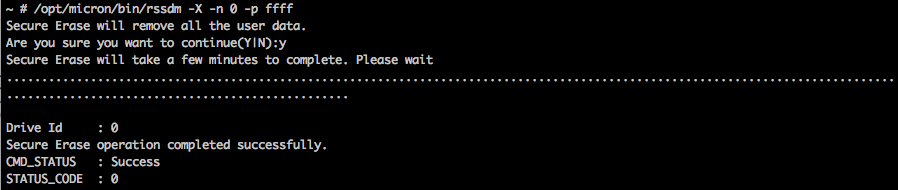
Note: For those interested, -X is to perform the secure erase, -n is to specify the drive ID, and -p is for password (default is ffff)
After the secure erase is complete, remove the host out of maintenance mode and add the device back to the FVP Cluster.

